
Execute Databricks notebooks in parallel
- Shamen Paris
- Feb 18, 2023
- 2 min read

If you are looking to run your notebooks simultaneously, I have found a way to do it. This can also be used to run a notebook with different parameters attached. Setting up databrick jobs for individual notebooks is another way to run the notebooks concurrently. But using a Python library called concurrent.futures, we can run the notebooks at the same time.
There are 2 methods can be used in concurrent.futures python library.
ThreadPoolExecutor
ProcessPoolExecutor
Assume there are three notebooks, and they were previously executed one after the other. And total execution time for all notebooks will be 18 seconds. (See below image)
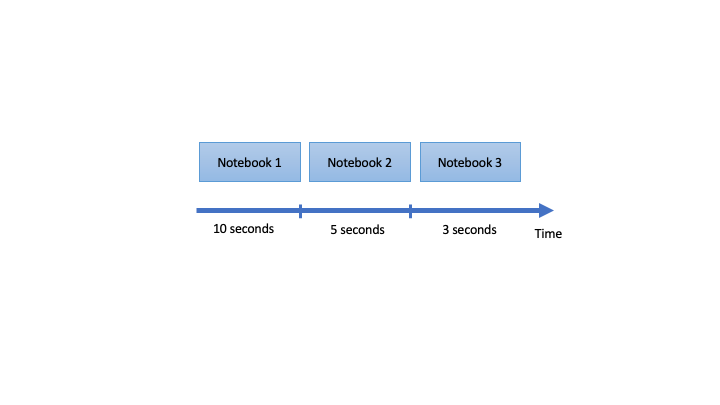
This can be done in parallel if there are no dependencies between the notebooks. Using ThreadPoolExecutor, we can run the notebook in parallel, but when the process runs, it creates a time gap before starting the next process.
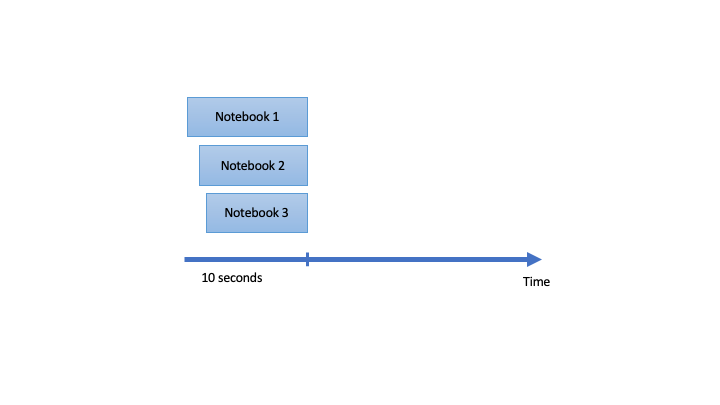
ProcessPoolExecutor can be used to run the notebooks without any time gaps.
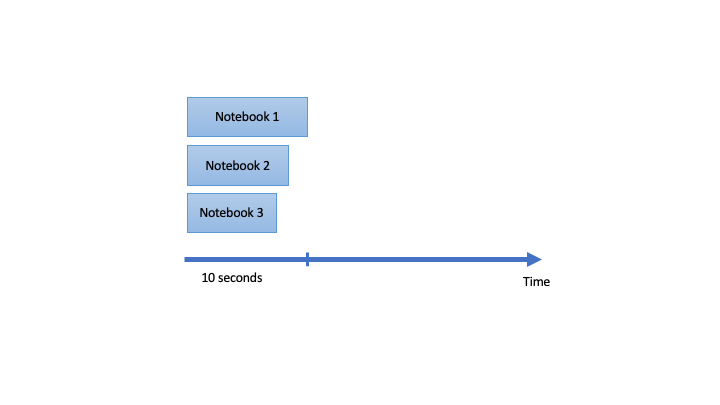
I prefer to use ThreadPoolExecutor to run the notebooks in parallel because there is a small time gap, which can be helpful to reduce the impact of the traffic block when running the jobs in cluster.
When you use the ThreadPoolExecutor to run the notebook in parallel, first you need to create a function to get the notebook path, parameters, and other relevant input to execute the notebook. See the below example, which required path, timeout, parameters, and retry as parameters to use the submitNotebook method.
from concurrent.futures import ThreadPoolExecutor
class NotebookData:
def __init__(self, path, timeout, parameters=None, retry=0):
self.path = path
self.timeout = timeout
self.parameters = parameters
self.retry = retry
def submitNotebook(notebook):
print("Running notebook %s" % notebook.path)
try:
if (notebook.parameters):
return dbutils.notebook.run(notebook.path, notebook.timeout, notebook.parameters)
else:
return dbutils.notebook.run(notebook.path, notebook.timeout)
except Exception:
if notebook.retry < 1:
raise
print("Retrying notebook %s" % notebook.path)
notebook.retry = notebook.retry - 1
submitNotebook(notebook)
Then create the objects using the function for each notebook. As in the previous examples, we have three notebooks that must run concurrently. So we can create the object for each notebook as below.
notebooks = [
NotebookData("/Path/Notebooks Parallel Run/notebook 1", 1200),
NotebookData("/Path/Notebooks Parallel Run/notebook 2", 1200),
NotebookData("/Path/Notebooks Parallel Run/notebook 3", 1200, retry=2)] To use the ThreadPoolExecutor to execute the notebooks in parallel, it was required to pass the created object (the notebooks) into the ThreadPoolExecutor. Then ThreadPoolExecutor will keep the object and start to run at the same time.
def NotebooksParallelRun(notebooks, pWorkers):
with ThreadPoolExecutor(max_workers=pWorkers) as exc:
return [exc.submit(NotebookData.submitNotebook, notebook) for notebook in notebooks]
NotebooksParallelRun(notebooks, 3)Check the notebook it will show the jobs at the output section below the command. It looks like below image.
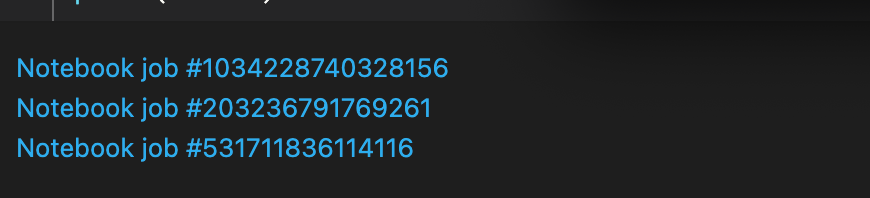
Conclusion:
With ProcessPoolExecutor or ThreadPoolExecutor, many notebooks can run simultaneously. When it comes to batch processing, this strategy is really helpful.
ThreadPoolExecutor - Use to execute process parallel with a time gap.
ProcessPoolExecutor - Use to execute process parallel without a time gap.


Comments